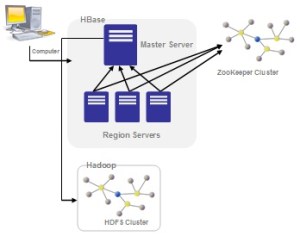
With the advent of the “Information Age”, massive amounts of data & information is being added into our lives every second. Gone are the days of MB & GB. Today everything is in the order of TB and PB. Raw data is worthless unless meaningful information can be extracted out of it & made searchable so that end users derive value.
Search plays the most integral role in today’s websites and online applications. Search has the power to make or break a business. Hence, sufficient time has to be spent to make search a meaningful experience to the users.
We will look at David & Goliath of search technologies – Amazon CloudSearch & Apache Solr.
Amazon CloudSearch is a “fully-managed search service in the cloud that allows customers to easily integrate fast and highly scalable search functionality into their applications. It seamlessly scales as the amount of searchable data increases or as the query rate changes, and developers can change search parameters, fine tune search relevance, and apply new settings at any time without having to upload the data again. It supports a rich set of features including free text search, faceted search, customizable relevance ranking, configurable search fields, text processing options, and near real-time indexing.
Apache Solr is a “popular, blazing fast open source enterprise search platform from the Apache Lucene project. Its major features include powerful full-text search, hit highlighting, faceted search, dynamic clustering, database integration, rich document (e.g., Word, PDF) handling, and geospatial search. Solr is highly scalable, providing distributed search and index replication.”
First, let’s compare these two search technologies with respect to their feature set –
Breed
Apache Solr is completely open source. It is written entirely in Java and uses Lucene under the hood. However, Amazon CloudSearch is a proprietary creation and is based on Amazon’s A9 technology.
Setup Effort
Considerable time & effort is needed to configure Apache Solr and get it up & running. It includes tasks such as Solr download, knowledge of Java, configuration of environment variables, deploying it in a server, understanding the commands needed to start / stop / index the Solr server, applying patches and upgrading to newer versions.
In contrast, Amazon CloudSearch is a fully managed search service in the cloud. You can set it up and start processing queries in less than an hour with a few clicks in the AWS Management Console. You don’t need to worry about running out of disk space or processing power.
Multilingual Support
Apache Solr has multilingual support. Custom analysers and tokenizers have to be written and plugged in. Also, the recommended approach is to have a multi-core architecture with each core addressing one language. But Amazon CloudSearch currently supports only English for tokenizing words in the index.
This is a good-to-have feature but cannot be seen as a critical one.
Scaling
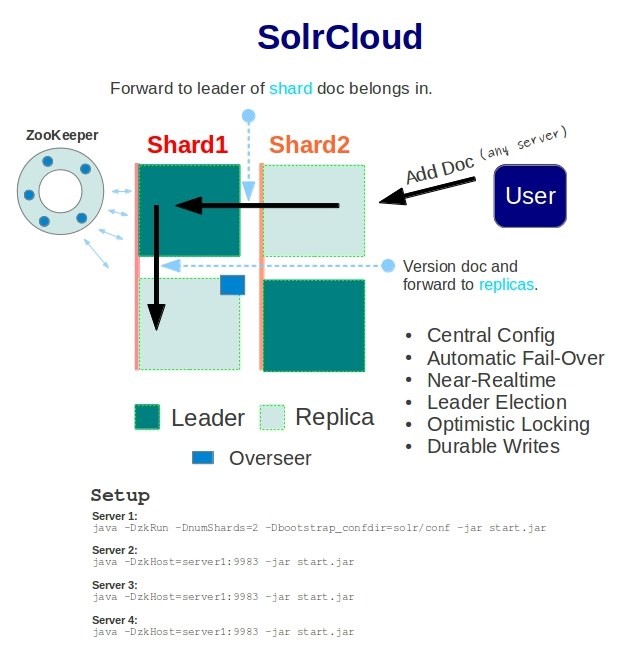
Scaling is an important design consideration for high volume / high growth architectures. Scaling can be done in two ways: scale-up & scale-out. Scale-up is the process of migrating from a small instance to a larger instance whereas scale-out is the process of spawning multiple instances. Refer Figure 1 below.
Apache Solr has scaling support but it is a manual process. When the search traffic increases beyond the threshold of a particular server, we have to manually spawn new Solr servers, transfer the index, auto-warm the caches and re-route the search queries to point to the new Solr servers. It is an involved process and needs an expert to get it done right.
An expert Solr admin is needed to keep a close watch on the performance of the Solr servers. Solr provides an admin interface, which has information regarding documentCache, filterCache, resultCache and statistics such as cache hit rate, cache lookups, cache hit ratio and cache size. Observing these metrics, the Solr admin has to decide on scaling the Solr server. One of the signals that an admin uses to make this decision is to have a look at the cache hit ratio. If this metric is low, then it means that the cache is not able to serve a majority of Solr search requests. The admin then proceeds to increase the cache size (i.e. scale-up) so that searches will be quicker. Similarly when a scale-up is not possible, scale-out comes in handy. But scale-out is not as easy an operation as scale-up. As you will see later in this article, scale-out involves partitioning the index and performing a distributed search. The admin needs to be careful when partitioning the index (as it usually leads to the re-index of the entire data set) and search queries have to be modified to support the presence of multiple indices across distributed Solr servers. Manual scaling is a strenuous task, no doubt.
As Amazon CloudSearch is a fully managed search service, it scales up and down seamlessly as the amount of data or query volume increases. Amazon CloudSearch determines the size and number of search instances required to deliver low latency, high throughput search performance. When a search instance reaches over 80% CPU utilization, CloudSearch scales up your search domain by adding a search instance to handle the increased traffic. Conversely, when a search instance reaches below 30% CPU utilization, CloudSearch scales down your search domain by removing the additional search instances in order to minimize costs. This is one of the most important points in favour of Amazon CloudSearch.
In today’s information age, scaling (along with index partitioning and replication) is considered as a must-have feature.
Partitioning the Index
When it is not possible to store the data in its entirety on a single server, we have to partition the index and store the part-indices in separate servers. This is also known as sharding.
Apache Solr supports partitioning the index but it is a manual process. When performed manually, it is not a completely transparent operation. Solr doesn’t have any logic for distributing indexed data over shards. Then when querying for data, you supply a shards parameter that lists which Solr shards to aggregate results from. Lastly, every document needs a unique key (ID), because you are breaking up the index based on rows, and these rows are distinguished from each other by their document ID.
uniqueId.hashCode() % numServers determines which server a document should be indexed at. The ability to search across shards is built into the query request handlers. You do not need to do any special configuration to activate it. In order to search across shards, you would issue a search request to Solr, and specify in a shards URL parameter a comma delimited list of all of the shards to distribute the search across. You can issue the search request to any Solr instance, and the server will in turn delegate the same request to each of the Solr servers identified in the shards parameter. The server will aggregate the results and return the standard response format. A sample distributed search URL will be of the form –
http://localhost:8983/solr/select?shards=localhost:8983/solr,localhost:7574/solr&indent=true&q=ipod+solr
Amazon CloudSearch, being a fully managed search service, automatically partitions the index as your data volume grows. It will partition the index across multiple search instances. Conversely, when your data volume shrinks, it will fit your data in one index.
Figure 1: CloudSearch Scaling showing index partition & replication
Replication of Index
Replication of index is used to handle high volumes of search traffic.
Apache Solr has the support to replicate the index. But it is a manual process and includes spawning new instances and configuring them to enable replication between the servers. A replication handler has to be configured on both master and slave machines. On the master, you have to specify the replicateAfter values and on the slave you have to set the fully qualified URL of the master replication handler for the attribute masterUrl. If at any time the URL of the master changes, then all the slaves have to be stopped to make the necessary changes and restarted again.
Amazon CloudSearch automatically scales your search domain to meet your traffic demands. As your traffic increases beyond the processing capacity of each search instance, the partition is replicated to provide additional capacity.
Faceted Search
Faceting allows you to categorize your results into sub-groups, which can be used as the basis for another search. In recent times, faceting has gained popularity by allowing users to narrow down search results in an easy-to-use and efficient way.
Faceting is best explained with the help of a picture (See Figure 2 below). As you can see, a search for “java programming” results in a lot of hits. Observe on the left side of the figure. You can clearly see that the search resulted in 3 facets (or sub-groups) using which you can narrow down your search. For example: if you click on “PDF” in the “Format” facet (see “Facet 2” in the figure), the search query now essentially means “java programming AND only pdf format”, thereby narrowing down the search space eventually leading you to better and convenient results. You can also observe that each member of a facet is accompanied by a number called Facet Count. In the “Format” facet, you can see “PDF (14)” which means that there are 14 “java programming” results in PDF format. The important aspect of facets is that as you go deeper using facets, the resultant search space is vastly reduced and hence the search will be considerably faster.
Both Apache Solr and Amazon CloudSearch allows the user to perform faceting with minimal effort.
Figure 2: Faceted Search
Field Weighting / Boosting
Field Weighting is a process of assigning different prominences to the same word when present in different places in a document. For example when the phrase “Harry Potter” is present in the title of a document, it is ranked higher than when the same phrase is present in the References section of a document.
Both Apache Solr and Amazon CloudSearch allows field boosting with minimal effort.
“Did you mean…” feature
One of the better ways to enhance the search experience is offering spelling corrections. This is sometimes presented at the top of search results with such text as “Did you mean …”. Many a times, a user might not know the correct spelling thus leading him to undesired results. Such a feature would vastly reduce users’ time and effort. It is sad when businesses deliberately skip this feature in order to show increased search traffic in their monthly / annual term sheets.
Apache Solr supports this with the Spellcheck search component. The recommended approach is to build a word corpus based on the index principally because your data will contain proper nouns and other words not present in a general-purpose dictionary.
Unfortunately, Amazon CloudSearch has no support for “Did you mean…” feature.
Autosuggest
A popular feature of most search applications is the auto-suggest feature where, as a user types their query into a text box, suggestions of popular queries are presented. The suggestions list is refined as additional characters are typed in. If you think about it for a minute, you will realize that this feature is even better than a “Did you mean…” feature.
Apache Solr has the support for autosuggest. It can be facilitated in many ways – NGramFilterFactory, EdgeNGramFilterFactory or TermsComponent. When used in conjunction with jQuery, it becomes a very powerful autosuggest experience for the user.
Amazon CloudSearch has no support for autosuggest feature.
Geospatial Search
Consider the following example – when a user performs a search for “Starbucks”, the search engine must show the nearest outlet based on the user’s current location. Location-aware search will always produce significantly better results and helps the user in finding the information more effectively and efficiently. This use-case signifies the importance of Geospatial search. In today’s on-the-go world, it is a must-have feature as it is a win-win situation for both users and businesses.
Apache Solr supports geospatial search through the implementation class solr.LatLonType. Actions such as sorting the results by distance and boosting documents by distance can be performed.
Amazon CloudSearch has a very limited geospatial search feature set. As of now, CloudSearch has the capability to return documents within a specific area. Missing features include sorting by geographical distance and faceting by distance.
“Find Similar” feature
This suggests similar records based on a particular record. It is similar to the “Find Similar” feature used by popular search engines. It is more common for applications to request it to be performed on just one document when a user requests it, which occurs at some point after a search. E-commerce sites benefit from this feature as research suggests that users typically compare products before making a transaction and are likely to buy a product which is better & hence slightly expensive than what they had initially intended to buy.
Apache Solr implements this using MoreLikeThisHandler or MoreLikeThisComponent.
Amazon CloudSearch currently does not support this feature.
Rich Documents
Support for rich documents (HTML, PDF, Word, etc.) is an essential feature of a search server. Data & information will be in different formats and it would be foolish to expect it only in certain formats. It is best if search servers provide an intuitive interface for ETL operations and natively support this feature.
Apache Solr has support for rich document parsing & indexing using Apache Tika.
Amazon CloudSearch expects data to be in Search Data Format (JSON & XML) and hence we need to use AWS Console or command line tools (cs-generate-sdf) to convert the rich text to sdf format.
Customizations
Specific features need not be supported natively because there might not be sufficient demand for them. In such cases, customizations play an important role. It is really a good-to-have feature as different businesses have different requirements and they would need the capability to customize appropriately to suit their needs.
Amazon CloudSearch, being a proprietary creation, does not allow for any customization either through plugin integration or via extending functionalities.
Apache Solr, being open source, allows of customizations of analysers, tokenizers, indexers, query analysis and the like through plugins and via extending the code base.
Having seen the differences between these two search technologies in terms of their feature set, let’s us now compare them with respect to the production environments and fitment –
Increasing / Decreasing / Spike Traffic
Scaling Apache Solr is a manual process and an admin has to spawn new instances, having a close look on the traffic patterns, well in advance so that traffic requests are not dropped.
However, Amazon CloudSearch is a fully managed service and hence no human intervention is needed for scaling. As mentioned earlier, when a search instance reaches over 80% CPU utilization, CloudSearch scales up your search domain by adding a search instance to handle the increased traffic. Conversely, when a search instance reaches below 30% CPU utilization, CloudSearch scales down your search domain by removing the additional search instances in order to minimize costs.
Support for protocols
Both Amazon CloudSearch and Apache Solr support HTTP & HTTPS. Amazon CloudSearch supports HTTPS and includes web service interfaces to configure firewall settings that control network access to your domain. The same but manual process is recommended for Solr too.
Algorithms
Apache Solr has many algorithms including cache implementations such as LRUCache and FastLRUCache. Solr, being open source, can be extended by adding our own algorithms. Since Amazon CloudSearch is proprietary, neither is there information on the algorithms being used nor can they be extended. But please bear in mind that the default CloudSearch algorithms will suffice for most applications.
High Availability
Amazon CloudSearch, like other AWS components, is a highly-available service. It completely automates the time consuming tasks of managing and scaling it. But in the case of Apache Solr, the high-availability has to be built manually which is a strenuous task.
Cost
Consider a sample e-commerce business: 100 MB of search data is present in their servers. Search traffic is likely to be 100,000 requests per day. 50 batch uploads per day, where each batch contains 1000 1 KB documents. Their entire index has to be re-built 4 times every month.
Based on the above requirements, cost of running Amazon CloudSearch 24 / 7 will be close to $87. The costs will definitely rise as the data and search traffic increases since larger and more search instances will be spawned to meet the growing needs. The plus side, however, is that all the managing and scaling tasks are automated.
Running Apache Solr on existing servers will have no additional cost when the deployments are in the small-to-medium range. Since there is no such thing called a free lunch, additional efforts & time will be spent in setting up high availability and scaling.
Few Limitations of CloudSearch
- Available only in US East region
- It can scale up to a maximum of 50 instances and partition up to 10 instances. Further scaling is likely on prior approval from AWS team
- The maximum batch size is 5 MB and the maximum document size is 1 MB
- Stopwords, synonyms dictionary size is limited
Apache Solr is a highly stable product with a rich feature set and high profile deployments but requires significant human effort to scale and manage it. Amazon CloudSearch is still in its infancy and has a lot of catching-up to do. But the most important benefit is that managing and scaling is completely automatic. It has a lot of promise and we are eagerly awaiting future enhancements!