We live in the Data Age!
Web has been growing rapidly in size as well as scale during the last 10 years and is showing no signs of slowing down. Statistics show that every passing year more data gets generated than all the previous years combined. Moore’s law not only holds true for hardware but for data being generated too. Without wasting time for coining a new phrase for such vast amounts of data, the computing industry decided to just call it, plain and simple, Big Data.
Apache Hadoop is a framework that allows for the distributed processing of such large data sets across clusters of machines. At its core, it consists of 2 sub-projects – Hadoop MapReduce and Hadoop Distributed File System (HDFS). Hadoop MapReduce is a programming model and software framework for writing applications that rapidly process vast amounts of data in parallel on large clusters of compute nodes. HDFS is the primary storage system used by Hadoop applications. HDFS creates multiple replicas of data blocks and distributes them on compute nodes throughout a cluster to enable reliable, extremely rapid computations.
Amazon EMR (Elastic MapReduce) simplifies big data processing, providing a managed Hadoop framework that makes it easy, fast, and cost-effective for you to distribute and process vast amounts of your data across dynamically scalable Amazon EC2 instances.
In this post, I will explain the components of EMR and when to use Spot Instances to lower AWS costs.
Amazon EMR
As mentioned earlier, Amazon EMR is a managed Hadoop framework. With just a click of a button or through an API call, you can have an EMR cluster up and running in no time. It is best suited for data crunching jobs such as log file analysis, data mining, machine learning and scientific simulation. You no longer need to worry about the cumbersome and time-consuming process of setup, management and fine tuning of Hadoop clusters.
Trend

Google Trends shows that popularity of both Hadoop and EMR is increasing. But look at the graph with a keen eye. What do you observe? Though Hadoop showed immense increase in capturing the user’s mind share initially, its popularity has started to plateau. Why, you ask? It is clearly because of the emergence of EMR and how it makes provisioning and management of Hadoop clusters super simple.
Instance Groups
Instance Groups are a collection of EC2 instances that perform a set of roles. There are three instance groups in EMR:
Master Instance Group
The Master Instance Group manages the entire Hadoop cluster and runs the YARN ResourceManager service and the HDFS NameNode service, amongst others. It monitors the health of the cluster. It also tracks the status of the jobs submitted to the cluster.
Currently, there can only be one Master Node for an EMR cluster.
Core Instance Group
The Core Instance Group contains all the core nodes of an EMR cluster. The core nodes executes the tasks submitted to the cluster by running the YARN NodeManager daemons. It also stores the HDFS data by running the DataNode daemon.
The number of core nodes required is decided based on the size of the dataset.
You can resize the Core Instance Group and EMR will attempt to gracefully terminate the instances, for example, when no YARN tasks are present. Since core nodes host HDFS, there is a risk of losing data whenever graceful termination is not possible.
Task Instance Group
The Task Instance Group contains all the task nodes of an EMR cluster. The task nodes only executes the tasks submitted to the cluster by running the YARN NodeManager daemons. They do not run the DataNode daemon or store data in HDFS. Hence, you can add and terminate task nodes at will as there is absolutely no risk of data loss.
Task Instance Group is optional. You can add up to 48 task groups.
Words of caution
Master Node is a single node and AWS itself does not provide high availability. If it goes down, then the cluster is terminated. Hence, AWS recommends having Master Node on an On-Demand instance for time-critical workloads.
Core Nodes can be multiple in number. Since they also hold data, downsizing should be done with extreme caution as it risks data loss. AWS recommends having Core Nodes on On-Demand instances.
Core Nodes come with a limitation: An EMR cluster will not be deemed “healthy” unless all the requested core nodes are up and running. Let’s say you requested 10 core nodes and only 9 were provisioned. The status of the EMR cluster will be “unhealthy”. Only when the tenth core node become active, will the status change to “healthy”.
Leveraging Spot Instances
Isn’t it fair to assume that all real-world applications are data-critical workloads? Given this situation, we can conclude that Master Instance Group and Core Instance Group should ideally be On-Demand instances.
For the sake of argument, let’s consider launching Master Instance Group and Core Instance Group on Spot Instances. In the case of Master Instance Group, if the Spot Instance is taken away then the entire EMR cluster will be terminated.
In the case of Core Instance Group, if a subset of the Core Nodes are taken away then the cluster needs to recover the lost data and rebalance HDFS. If we lose majority or all of the Core Nodes, then we are bound to lose the entire cluster as data recovery from the available nodes will be impossible.
Core Instance Group have another limitation: They can only be of one instance type. You cannot launch a few Spot Instances in say m3.large and the rest in say c4.large.
There is also the question of “What is the best bid price for a Spot Instance?”. Careful examination of Spot Pricing History and understanding Spot Price variance is a must. It is no child’s play.
Running Task Instance Group on Spot Instances is a perfect match for time-insensitive workloads. As mentioned earlier, you can have up to 48 Task Instance Groups. This helps us in hedging the risk of losing all Spot Instances. For example, you can provision some Spot Instances in m3.large, a couple in m4.large and the rest in m1.large. There is no restriction, like Core Instance Group, that all requested Spot Instances have to be up and running. Even if only a subset of the Task Instance Group is up, the EMR status is considered “healthy” and the job execution continues.
Launching Task Instance Groups as Spot Instances is a good way to increase the cluster capacity while keeping costs at a minimum. A typical EMR cluster configuration is to launch Master Instance Group and Core Instance Group as On-Demand instances as they are guaranteed to run continuously. You can then add Task Instance Groups as needed to handle peak traffic and / or speed up data processing.
A caveat: You cannot remove a Task Instance Group once it is created. You can however decrease the task nodes count to zero. Since a maximum of 48 Task Instance Groups are allowed, be careful in choosing the instance types. You can neither change the instance type nor its bid price later on.
Batch.ly EMR in action
“Enough talk, show me the numbers.”, you demand? Thanks for asking!

A 2TB GDELT dataset was analyzed with custom Hive scripts. The Master Instance Group and the Core Instance Group were on On-Demand instances. The Task Instance Group was entirely on Spot Instances. A total of 5035 Spot Instance hours were required to complete the job. The total cost of running this job entirely on On-Demand instances would have been 689.79 USD. Since Batch.ly launched 100% of Task Nodes on Spot Instances, the cost was only 109.76 USD resulting in a massive savings of
Batch.ly additionally provides autoscaling of Task Nodes, i.e. you don’t have to worry about over-provisioning of instances, and also the ability to run your Master Node / Core Nodes on Spot Instances (gives you the choice) making it a compelling and easier option to use for running EMR workloads. Register now for a free 14-day trial of Batch.ly
After this, we can add that – Batch.ly additionally provides autoscaling of task nodes (where by you don’t have to worry about over provisioning of instances) and also the ability to run your Master / Core nodes on spot (gives you the choice) making it a compelling and easier option to use for running EMR workloads.
X-Post from cmpute.io blog



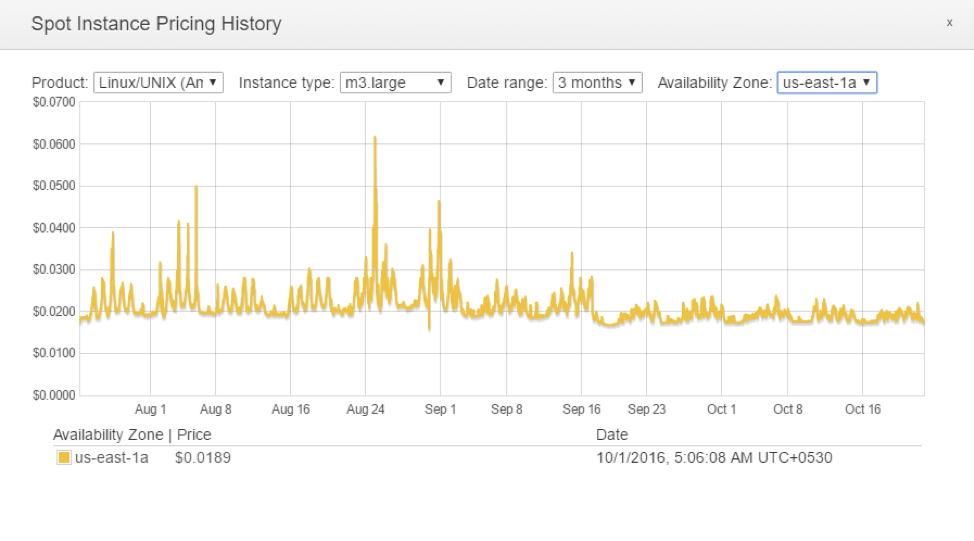 us-east-1a shows five tiny spikes in Spot Price while us-east-1d shows three. Clearly, us-east-1d is the slightly better Availability Zone.
us-east-1a shows five tiny spikes in Spot Price while us-east-1d shows three. Clearly, us-east-1d is the slightly better Availability Zone.







{kind=link}
{kind=link}