
“How do we optimally bid for Spot Instances to ensure that it is retained for the duration of the workload?” Simple question, right? Yes. Are you kidding? No, it is the answer that is complex! The more you dig into it, the more you realize how deep the web really is.
In this post, I will give you a peek into Spot Instances retainment strategies to employ for running your workloads with ease. This post is an embodiment of the adage, “A picture is worth a thousand words.”
Spot Instances
A recap – Spot Instances are spare computing capacity available at deeply discounted prices. AWS allows users to bid on unused EC2 capacity in a region at any given point and run those instances for as long as their bid exceeds the current Spot Price. The Spot Price changes periodically based on supply and demand, and all users bids that meet or exceed it gain access to the available Spot Instances.
Retention Strategies
Spot Instances, by design, can be taken away from you anytime. Retaining a Spot Instance isn’t just about bidding at an optimum price. Lots of other considerations have to be thought through. Name a few, you ask? Sure, here goes –
- Choosing an optimum Bid Price
- Selecting a (similar) instance type
- Opting for the right Availability Zone
Typical Workload Scenario
Consider the following example: A batch workload, running daily at 12:00AM UTC+0530, picks files from an S3 bucket, transcodes those into HD format, and stores the results back into the same bucket. The entire process takes 8 hours on an m3.large instance.
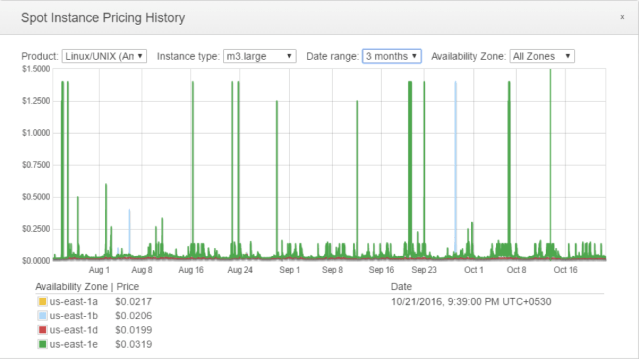
The above graph shows the Spot Instance Pricing History for m3.large for the last 3 months. There are lots of spikes in us-east-1e. It is definitely not a good Availability Zone to launch our Spot Instances. us-east-1b has two spikes. It is better than us-east-1e, but we can do better. us-east-1a and us-east-1d have no spikes at all. These are the Availability Zones you should prefer as a first step.
Between us-east-1a and us-east-1d, which is the better Availability Zone? Let’s look at their Spot Instance Pricing History separately.
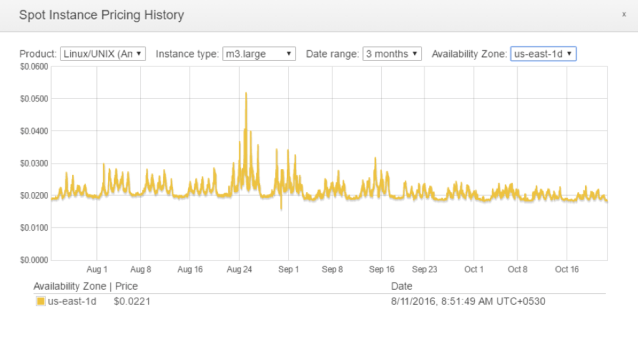
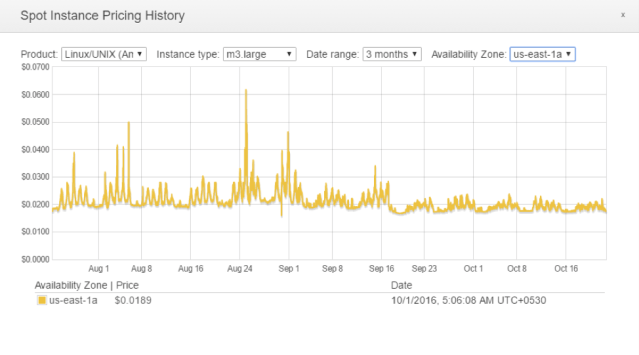 us-east-1a shows five tiny spikes in Spot Price while us-east-1d shows three. Clearly, us-east-1d is the slightly better Availability Zone.
us-east-1a shows five tiny spikes in Spot Price while us-east-1d shows three. Clearly, us-east-1d is the slightly better Availability Zone.
Setting the bid price at 0.055 USD or more will ensure that m3.large Spot Instances will be retained for the duration of the workload.
What if you want to run your workload on m4.large?

It is apparent that all Availability Zones have huge spikes. m4.large itself is not a good instance type. We should now start considering similar instances.
m4.large has a hardware specification – 2 vCPU and 8 Mem (GiB). Similar instances, considering a percentage variance of Mem (GiB), would be m3.large – 2 vCPU and 7.5 Mem (GiB) and c4.xlarge – 4 vCPU and 7.5 Mem (GiB).

Again, us-east-1e has a high spike occurrence. The safest Availability Zone would be us-east-1d. The Spot Instance Pricing History of us-east-1d for c4.xlarge is –
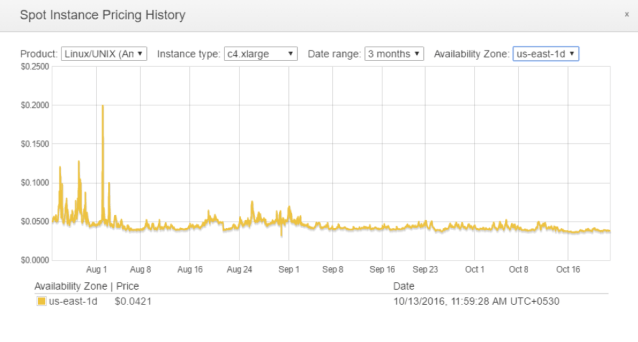
The average Spot Price for c4.xlarge hovers around 0.04 USD, while that of m3.large is 0.02 USD. The most similar instance for m4.large, with all else being equal, is m3.large and you should choose this instance and run your workload in us-east-1d at a bid price of 0.055 USD.
Did you notice the complex set of steps involved in choosing the right Availability Zone, zeroing in on the best instance type, and setting the optimum bid price? Now extrapolate it to 14 regions, 38 Availability Zones, and 600+ bidding variations. We haven’t even considered when is a good time to run your workload. If your workload start times can be flexible, give or take a few hours, then you might get an additional savings of up to 15%. And yes, we are getting our hands dirty in the elusive domains of Pattern Recognition and Machine Learning.
X-Post from cmpute.io blog

