Solr is the popular, blazing fast open source enterprise search platform from the Apache Lucene project. Its major features include powerful full-text search, hit highlighting, faceted search, near real-time indexing, dynamic clustering, database integration, rich document (e.g., Word, PDF) handling, and geospatial search. Solr is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. Solr powers the search and navigation features of many of the world’s largest internet sites.
The major feature introductions in Solr 4.0 are SolrCloud, Near Real Time Search, Atomic Updates and Optimistic Concurrency. Before getting into the details, first let’s understand how distributed indexing & querying and master-slave index replication worked in Solr 3.6 or earlier.
Solr in AWS: Shards & Distributed Search provides a detailed explanation of what a shard is, initializing shards, indexing documents into shards and performing a distributed search. Learnings from this article are as follows –
- Solr doesn’t have any logic for distributing indexed data over shards. It is up to you to ensure that the documents are evenly distributed across shards.
- Performing a distributed search requires you to have knowledge of all the existing shards so that the entire data set can be queried.
- Both distributed indexing and querying is NOT a transparent process
- What happens when one of the shards goes down? Is the data incomplete now?
Distributed indexing & searching is a very significant feature, no doubt. But can it be handled better and in a much more transparent way?
Solr in AWS: Master Slave Replication & Mitigation Strategies offers a detailed explanation of what an index replication means, setting it up in master-slave mode and mitigation steps needed when the master fails. Learnings from this article are as follows –
- Master is the single point of failure (SPOF). Once the master is down, no more writes to the index are possible.
- Master has no clue of the number of slaves that are present.
- Absence of a centralized coordination service for maintaining configuration information and providing distributed synchronization leading to inevitable race conditions.
- Replication is done pull-style which leads to index inconsistencies due to replication lag
- Nomination of one of the slaves as the new master requires implementation of custom scripts and / or deployment of NFS.
- What happens when the master goes down and you do not receive any notification?
It is obvious that setting up distributed indexing & searching and master-slave replication is a complex process and requires the presence of a Solr expert.
Do not fret! Enter Solr 4.0 and its state-of-the-art capabilities.
SolrCloud
SolrCloud is the name of a set of new distributed capabilities in Solr. Passing parameters to enable these capabilities will enable you to set up a highly available, fault tolerant cluster of Solr servers. Use SolrCloud when you want high scale, fault tolerant, distributed indexing and search capabilities.
Truth be told – Setting up a sharded, replicated, highly available, fault tolerant SolrCloud cluster takes less than 15 minutes! Ok, enough of the theatrics. Let’s get our hands dirty.
A SolrCloud cluster consists of one or more shards, each having one or more replicas and coordinated by ZooKeeper to facilitate high availability and fault tolerance.
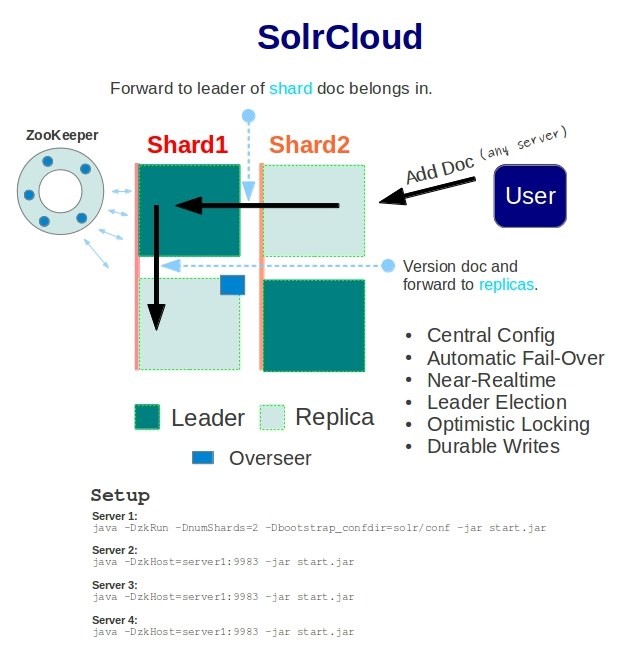
Figure 1: 2 Shard 2 Replica Architecture
ZooKeeper
ZooKeeper is used as a repository for cluster configuration and coordination – think of it as a distributed file system that contains information about all of the Solr servers. A single ZooKeeper service can handle the cluster but then it becomes SPOF. In order to avoid such a scenario, it is recommended that a ZooKeeper Ensemble, i.e. running multiple ZooKeeper servers in concert, is in action. Every ZooKeeper server needs to know about every other ZooKeeper server in the ensemble, and a majority of servers (called a Quorum) are needed to provide service. For example, a ZooKeeper ensemble of 3 servers allows anyone to fail with the remaining 2 constituting a majority to continue providing service. 5 ZooKeeper servers are needed to allow for the failure of up to 2 servers at a time.
Installing & running ZooKeeper Ensemble
cd /opt wget http://apache.techartifact.com/mirror/zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz tar -xzvf zookeeper-3.4.5.tar.gz cd zookeeper-3.4.5 cp conf/zoo_sample.cfg conf/zoo.cfg vim conf/zoo.cfg dataDir=/opt/zookeeper/data server.1=<ip>:<quorum_port>:<leader_election_port> server.2=<ip>:<quorum_port>:<leader_election_port> server.3=<ip>:<quorum_port>:<leader_election_port> cd /opt/zookeeper/data vim myid 1 (or 2 or 3… depending on the server) /opt/zookeeper-3.4.5/bin/zkServer.sh start /opt/zookeeper-3.4.5/bin/zkServer.sh stop
Follow the above steps in all the ZooKeeper servers. Refer Clustered (Multi-Server) Setup and Configuration Parameters for understanding quorum_port, leader_election_port and the file myid. We now have a 3-node ZooKeeper Ensemble running!
Installing & running Solr 4.0
cd /opt wget http://apache.techartifact.com/mirror/lucene/solr/4.0.0/apache-solr-4.0.0.tgz tar -xzvf apache-solr-4.0.0.tgz rm -f apache-solr-4.0.0.tgz cd /opt/apache-solr-4.0.0/example/ java -Dbootstrap_confdir=./solr/collection1/conf -Dcollection.configName=myconf -DnumShards=2 -DzkHost=<server1_ip>:<client_port>,<server2_ip>:<client_port>,<server3_ip>:<client_port> -jar start.jar java -DzkHost= DzkHost=<server1_ip>:<client_port>,<server2_ip>:<client_port>,<server3_ip>:<client_port> -jar start.jar
A couple of points worth mentioning –
-DnumShards: the number of shards that will be present. Note that once set, this number cannot be increased or decreased without re-indexing the entire data set. (Dynamically changing the number of shards is part of the Solr roadmap!)-DzkHost: a comma-separated list of ZooKeeper servers.-Dbootstrap_confdir,-Dcollection.configName: these parameters are specified only when starting up the first Solr instance. This will enable the transfer of configuration files to ZooKeeper. Subsequent Solr instances need to just point to the ZooKeeper ensemble.
The above command with –DnumShards=2 specifies that it is a 2-shard cluster. The first Solr server automatically becomes shard1 and the second Solr server automatically becomes shard2. What happens when we run a third & fourth Solr instances? Since it’s a 2-shard cluster, the third Solr server automatically becomes a replica of shard1 and the fourth Solr server becomes a replica of shard2. We now have 4-node (2-shard 2-replica) Solr cluster running!
An important point to remember: The first Solr server that joins shard1 is assigned the role of a Leader of the shard1 sub-cluster and subsequent servers that join shard1 are the replicas. All writes happen on the Leader and the same are pushed to the replicas. If the Leader goes down, automatic fail over kicks in and a replica will automatically be promoted to the role of the Leader.
Indexing documents into the cluster
Unlike pre Solr 4.0, the entire indexing process is transparent. Any document write operation can be sent to any shard leader / replica and the indexing module ensures that the document is sent to the correct shard.
The index process is as follows –
- If an index document request is sent to a shard replica, the same is forwarded to the leader of that shard.
- If an index document request is sent to a leader of a shard, then the leader first checks if the document belongs to the same shard using MurmurHash3 algorithm.
- If yes, then the document is written to its transaction log.
- If no, then the document is forwarded to the leader of the correct shard which in turn writes to its transaction log.
It then transfers the delta of the transaction log to all its replicas. The replicas in turn update their respective transaction logs and send an acknowledgement to the leader. Once the leader receives acknowledgements that all the slaves have received the updates, the original index request is responded to.
Performing a distributed search
Unlike pre Solr 4.0, the entire distributed search is completely transparent. You need not know the number of shards nor the number of replicas. All this information is maintained in ZooKeeper.
When a query request is sent to one of the instances, either a leader or a replica, Solr load balances the requests across replicas, using different servers to satisfy each request. SolrCloud can continue to serve results without interruption as long as at least one server hosts every shard. To return just the documents that are available in the shards that are still alive (and avoid a 503 error), add the following query parameter: shards.tolerant=true.
Soft Commit
A hard commit calls fsync on the index files to ensure that they have been flushed to stable storage and no data loss will result from a power failure. It is an expensive operation as it involves disk IO.
A soft commit, introduced in Solr 4.0 to handle NRT search, is much faster as it only makes the index change visible to the searchers but does not call fsync. This is accomplished by writing the changes to the transaction log. Think of it as adding documents to an in-memory writeable segment. As the size of the transaction log increases over time, it is imperative that these are written to disk using hard commit periodically.
Near Real Time Search
The /get NRT handler ensures that the latest version of a document is retrieved. It is NOT designed to be used as full-text search. Instead, its responsibility is the guaranteed return of the latest version of a particular document.
When a /get request is raised by providing an id or ids (a set of id), the search process is as follows –
- It checks if the document is present in the transaction log
- If yes, then the document is returned from the transaction log
- If no, then the latest opened searcher is used to retrieve the document
Atomic Updates
Atomic Updates is a new feature in Solr 4.0 that allows you to update on a field level rather than on a document level (pre Solr 4.0). This means that you can update individual fields without having to send the entire document to Solr with the update fields’ values. Internally Solr re-adds the document to the index with the updated fields. Please note that fields in your schema.xml must be stored=true to enable atomic updates.
Optimistic Concurrency
Optimistic concurrency control is a Solr NoSQL feature that allows a conditional update based on the document _version_. Using optimistic concurrency normally involves a READ-MODIFY-WRITE process. Solr automatically adds a _version_ field to all documents. A client can specify a value for _version_ on any update operation to invoke optimistic concurrency control.
- If the value of
_version_matches what currently exists in Solr, then the update operation will be successful and a new_version_value will be set to that document. - If the
_version_does not match what currently exists in Solr, then a HTTP error with code 409 (Conflict) will be returned.
FAQ
- How are the replicas assigned to shards?
- When a new Solr server is added, it is assigned to the shard with the fewest replicas, tie-breaking on the lowest shard number.
- Why should I specify all the ZooKeepers for the parameter –DzkHost?
- TCP connections are established between the Solr instance and the ZooKeeper servers. When a ZooKeeper server goes down, the corresponding TCP connection is lost. However, other existing TCP connections are still functional and hence this ensures fault tolerance of the SolrCloud cluster even when one or more ZooKeeper servers are down.
- What is a transaction log?
- It is an append-only log of write operations maintained by each node. It records all write operations performed on an index between two commits. Anytime the indexing process is interrupted, any uncommitted updates can be replayed from the transaction log.
- When does the old-style replication kick in?
- When a Solr machine is added to the cluster as a replica, it needs to get itself synchronized with the concerned shard. If more than 100 updates are present, then an old-style master-slave replication kicks off. Otherwise, transaction log is replayed to synchronize the replica.
- How is load balancing performed on the client side?
- Solr client uses LBHttpSolrServer. It is a dumb round-robin implementation. Please note that this should NOT be used for indexing.
- What will happen if the entire ZooKeeper ensemble goes down or quorum is not maintained?
- ZooKeeper periodically sends the current cluster configuration information to all the SolrCloud instances. When a search request needs to be performed, the Solr instance reads the current cluster information from its local cache and executes the query. Hence, search requests need not have the ZooKeeper ensemble running. Please bear in mind that any new instances that are added to the cluster will not be visible to the other instances.
- However, a write index request is a bit more complicated. An index write operation results in a new Lucene segment getting added or existing Lucene segments getting merged. This information has to be sent to ZooKeeper. Each Solr server must report to ZooKeeper which cores it has installed. Each host file is of the form host_version. It is the responsibility of each Solr host/server to match the state of the cores_N file. Meaning, each Solr server must install the cores defined for it and after successful install, write the hosts file out to ZooKeeper. Hence, an index write operation always needs ZooKeeper ensemble to be running.
- Can the ZooKeeper cluster be dynamically changed?
- ZooKeeper cluster is not easily changed dynamically but is part of their roadmap. A workaround is to do a Rolling Restart.
- Is there a way to find out which Solr instance is a leader and which one is a replica?
- Solr 4.0 Admin console shows these roles in a nice graphical manner.
- How much time does it take to add a new replica to a shard?
- For a shard leader index size of 500MB, an
m1.mediumEC2 cold-start replica instance takes about 30 seconds to synchronize its index with the leader and become part of the cluster.
- For a shard leader index size of 500MB, an
- Is it possible to ensure that the SolrCloud cluster is HA even when an entire AZ goes out of action?
- When an entire AZ is down and the cluster is expected to be running successfully, the simplest and recommended approach is to have all leaders in one AZ and replicas in other AZs with the ZooKeeper ensemble spanning across AZs.
References
- http://wiki.apache.org/solr/SolrCloud
- http://zookeeper.apache.org/
- http://wiki.apache.org/solr/SolrReplication
- https://pristinecrap.com/2013/01/12/solr-in-aws-shards-distributed-search/
- http://wiki.apache.org/solr/UpdateXmlMessages
- http://wiki.apache.org/solr/Atomic_Updates
- http://yonik.com/solr/realtime-get/
- http://yonik.com/solr/optimistic-concurrency/


What will happen if the entire ZooKeeper ensemble goes down or quorum is not maintained?
ZooKeeper sends the current cluster configuration information to all the SolrCloud instances.
How come ZK will send this info? since the whole ensemble is down! Solr can have this info and do this?
What will happen if the entire ZooKeeper ensemble goes down or quorum is not maintained?
ZooKeeper sends the current cluster configuration information to all the SolrCloud instances.
How come ZK will send this info? Since the whole ensemble is down? Can Solr have this info and do ?
Loved the article. We are currently using Solr 3.5 on our system, an upgrade is imminent, but I am more than happy that Solr now supports distribution inherently. Thanks.
@Ramprasad: ZooKeeper “periodically” sends the cluster configuration information to all the Solr instances.
I have updated the article accordingly.
@Ritesh: Thanks for reading my article.
Solr 4.0 is the best yet. A lot of “cloud” features are added. Maybe they see a real threat for the first time in Amazon CloudSearch 🙂