We live in the data age! Web has been growing rapidly in size as well as scale during the last 10 years and shows no signs of slowing down. Statistics show that every passing year more data gets generated than all the previous years combined. Moore’s law not only holds true for hardware but for data being generated too. Without wasting time for coining a new phrase for such vast amounts of data, the computing industry decided to just call it, plain and simple, Big Data.
More than structured information stored neatly in rows and columns, Big Data actually comes in complex, unstructured formats, everything from web sites, social media and email, to videos, presentations, etc. This is a critical distinction, because, in order to extract valuable business intelligence from Big Data, any organization will need to rely on technologies that enable a scalable, accurate, and powerful analysis of these formats.
The next logical question arises – How do we efficiently process such large data sets? One of the pioneers in this field was Google, which designed scalable frameworks like MapReduce and Google File System. Inspired by these designs, an Apache open source initiative was started under the name Hadoop. Apache Hadoop is a framework that allows for the distributed processing of such large data sets across clusters of machines.
Apache Hadoop, at its core, consists of 2 sub-projects – Hadoop MapReduce and Hadoop Distributed File System. Hadoop MapReduce is a programming model and software framework for writing applications that rapidly process vast amounts of data in parallel on large clusters of compute nodes. HDFS is the primary storage system used by Hadoop applications. HDFS creates multiple replicas of data blocks and distributes them on compute nodes throughout a cluster to enable reliable, extremely rapid computations. Other Hadoop-related projects at Apache include Chukwa, Hive, HBase, Mahout, Sqoop and ZooKeeper.
High level architecture of Hadoop Ecosystem

HDFS
When a dataset outgrows the storage capacity of a single physical machine, it becomes necessary to partition it across a number of separate machines. Filesystems that manage the storage across a network of machines are called distributed filesystems. HDFS is designed for storing very large files with write-once-ready-many-times patterns, running on clusters of commodity hardware. HDFS is not a good fit for low-latency data access, when there are lots of small files and for modifications at arbitrary offsets in the file.
Files in HDFS are broken into block-sized chunks, default size being 64MB, which are stored as independent units.
An HDFS cluster has two types of node operating in a master-worker pattern: a NameNode(the master) and a number of DataNodes (workers). The namenode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files and directories in the tree. The namenode also knows the datanodes on which all the blocks for a given file are located. Datanodes are the workhorses of the filesystem. They store and retrieve blocks when they are told to (by clients or the namenode), and they report back to the namenode periodically with lists of blocks that they are storing.
MapReduce
MapReduce is a framework for processing highly distributable problems across huge datasets using a large number of computers (nodes), collectively referred to as a cluster. The framework is inspired by the map and reduce functions commonly used in functional programming.
In the “Map” step, the master node takes the input, partitions it up into smaller sub-problems, and distributes them to worker nodes. The worker node processes the smaller problem, and passes the answer back to its master node. In the “Reduce” step, the master node then collects the answers to all the sub-problems and combines them in some way to form the output – the answer to the problem it was originally trying to solve.
There are two types of nodes that control this job execution process: a JobTrackerand a number of TaskTrackers. The jobtracker coordinates all the jobs run on the system by scheduling tasks to run on tasktrackers. Tasktrackers run tasks and send progress reports to the jobtracker, which keeps a record of the overall progress of each job. If a task fails, the jobtracker can reschedule it on a different tasktracker.

Chukwa
Chukwa is a Hadoop subproject devoted to large-scale log collection and analysis. Chukwa is built on top of HDFS and MapReduce framework and inherits Hadoop’s scalability and robustness. It has four primary components:
- Agents that run on each machine and emit data
- Collectors that receive data from the agent and write to a stable storage
- MapReduce jobs for parsing and archiving the data
- HICC, Hadoop Infrastructure Care Center; a web-portal style interface for displaying data
Flume from Cloudera is similar to Chukwa both in architecture and features. Architecturally, Chukwa is a batch system. In contrast, Flume is designed more as a continuous stream processing system.

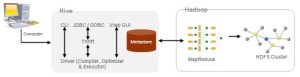
Hive
Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query and analysis.
Using Hadoop was not easy for end users, especially for the ones who were not familiar with MapReduce framework. End users had to write map/reduce programs for simple tasks like getting raw counts or averages. Hive was created to make it possible for analysts with strong SQL skills (but meager Java programming skills) to run queries on the huge volumes of data to extract patterns and meaningful information. It provides an SQL-like language called HiveQL while maintaining full support for map/reduce. In short, a Hive query is converted to MapReduce tasks.
The main building blocks of Hive are –
- Metastore stores the system catalog and metadata about tables, columns, partitions, etc.
- Driver manages the lifecycle of a HiveQL statement as it moves through Hive
- Query Compiler compiles HiveQL into a directed acyclic graph for MapReduce tasks
- Execution Engine executes the tasks produced by the compiler in proper dependency order
- HiveServer provides a Thrift interface and a JDBC / ODBC server
HBase
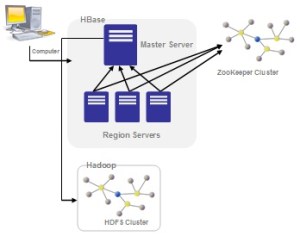
As HDFS is an append-only filesystem, the need for modifications at arbitrary offsets arose quickly. HBase is the Hadoop application to use when you require real-time read/write random-access to very large datasets. It is a distributed column-orienteddatabase built on top of HDFS. HBase is not relational and does not support SQL, but given the proper problem space, it is able to do what an RDBMS cannot: host very large, sparsely populated tables on clusters made from commodity hardware.
HBase is modeled with an HBase master node orchestrating a cluster of one or more regionserver slaves. The HBase master is responsible for bootstrapping a virgin install, for assigning regions to registered regionservers, and for recovering regionserver failures. The regionservers carry zero or more regions and field client read/write requests.
HBase depends on ZooKeeper and by default it manages a ZooKeeper instance as the authority on cluster state. HBase hosts vital information such as the location of the root catalog table and the address of the current cluster Master. Assignment of regions is mediated via ZooKeeper in case participating servers crash mid-assignment.
Mahout
The success of companies and individuals in the data age depends on how quickly and efficiently they turn vast amounts of data into actionable information. Whether it’s for processing hundreds or thousands of personal e-mail messages a day or divining user intent from petabytes of weblogs, the need for tools that can organize and enhance data has never been greater. Therein lies the premise and the promise of the field of machine learning.
How do we easily move all these concepts to big data? Welcome Mahout!
Mahout is an open source machine learning library from Apache. It’s highly scalable. Mahout aims to be the machine learning tool of choice when the collection of data to be processed is very large, perhaps far too large for a single machine. At the moment, it primarily implements recommender engines (collaborative filtering), clustering, and classification.
Recommender engines try to infer tastes and preferences and identify unknown items that are of interest. Clustering attempts to group a large number of things together into clusters that share some similarity. It’s a way to discover hierarchy and order in a large or hard-to-understand data set. Classification decides how much a thing is or isn’t part of some type or category, or how much it does or doesn’t have some attribute.

Sqoop
Loading bulk data into Hadoop from production systems or accessing it from map-reduce applications running on large clusters can be a challenging task. Transferring data using scripts is inefficient and time-consuming.
How do we efficiently move data from an external storage into HDFS or Hive or HBase? Meet Apache Sqoop. Sqoop allows easy import and export of data from structured data stores such as relational databases, enterprise data warehouses, and NoSQL systems. The dataset being transferred is sliced up into different partitions and a map-only job is launched with individual mappers responsible for transferring a slice of this dataset.

ZooKeeper
ZooKeeper is a distributed, open-source coordination service for distributed applications. It exposes a simple set of primitives that distributed applications can build upon to implement higher level services for synchronization, configuration maintenance, and groups and naming.
Coordination services are notoriously hard to get right. They are especially prone to errors such as race conditions and deadlock. The motivation behind ZooKeeper is to relieve distributed applications the responsibility of implementing coordination services from scratch.
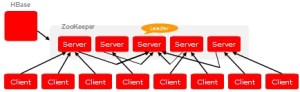
ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchical namespace which is organized similarly to a standard file system. The name space consists of data registers – called znodes, and these are similar to files and directories. ZooKeeper data is kept in-memory, which means it can achieve high throughput and low latency numbers.
This article is published at CloudStory - Part 1, Part 2 & Part 3

